

Vad är NoSQL och RavenDB egentligen?
Under de senaste veckorna har vi börjat testa och labba med RavenDB på allvar för att kunna utvärdera och använda det som databas fullt ut även i skarpa kundprojekt. I den här bloggen går jag igenom hur vi byggt om en liten del av ett befintligt system med RavenDB som databas.
Hur ska man tänka med NoSQL?
Först och främst så är väl ett par ord om RavenDB på sin plats. RavenDB är en Open Source dokumentdatabas, eller en NoSQL-databas, byggd och använd primärt i .NET. RavenDB är gratis för Open Source-lösningar men kostar 25 USD per månad per instans för kommersiella projekt. En dokumentdatabas lagrar data som dokument istället för tabellrader och just RavenDB sparar JSON-objekt formaterade som strängar.
Man skulle kunna säga att man i en relationsdatabas strävar efter att spara data så effektivt som möjligt, uppdelat i tabeller och väl normaliserat för att spara plats och för att kunna garantera konsistens, medan man i RavenDB och andra dokumentdatabaser istället strävar efter att hämta data så effektivt som möjligt och därmed ska försöka spara precis den information som man sedan kommer att vilja hämta upp samtidigt.
Vikten av index
En stor skillnad mellan relationsdatabaser och NoSQL är att man inte kan ställa beräkningsfrågor utan att använda ett index. I en relationsdatabas sker dynamisk beräkning när en fråga ställs medan NoSQL-databaser behöver ett index för att ställa samma fråga.
En SQL Server kan alltså enkelt leverera svaret på följande fråga:
Med NoSQL måste man först definiera ett index som väljer ut och sorterar informationen på det sätt man vill fråga efter den. I andra NoSQL databaser än RavenDB är detta ett ganska tidskrävande arbete men RavenDB har en inbyggd analysdel som hjälper till att skapa dynamiska index i bakgrunden vilket gör arbetet väldigt mycket enklare, och startsträckan för att komma igång, kortare. I RavenDB skulle ovanstående fråga se ut så här (i LINQ):
För den frågan skulle RavenDB skapa ett dynamiskt index i bakgrunden. Det namnges dessutom automatiskt till ett väldigt lättläst namn: Auto/Users/ByUserName
Den här skillnaden kan vara svår att förstå i början om man är van vid att snabbt få tillgång till sin data med t ex SQL Server, men just det här är den absolut största fördelen med NoSQL eftersom det är anledningen till att NoSQL-databaser både klarar av större datamängder och att skalas "på bredden". Man ska dock tänka på att RavenDB bara klarar av att skapa automatiska index för enkla frågor. För mer avancerade beräkningar behöver du skapa egna index!
I RavenDB påverkar index inte prestandan när data sparas men i gengäld kan man få tillbaka ett resultat som inte är uppdaterat. När ett index skapas eller förändras, eller data förändras, ställs en fråga i bakgrunden för att hålla datan uppdaterad. Frågor du ställer mot ett index kommer att returneras direkt men om indexet samtidigt uppdateras av RavenDB kommer resultatet vara från ett tidigare indexeringstillfälle och markerat som Stale (vet du med dig att du bara vill ha fräscha resultat kan du förstås välja att vänta ut indexeringen med ett enkelt metodanrop).
Vår data
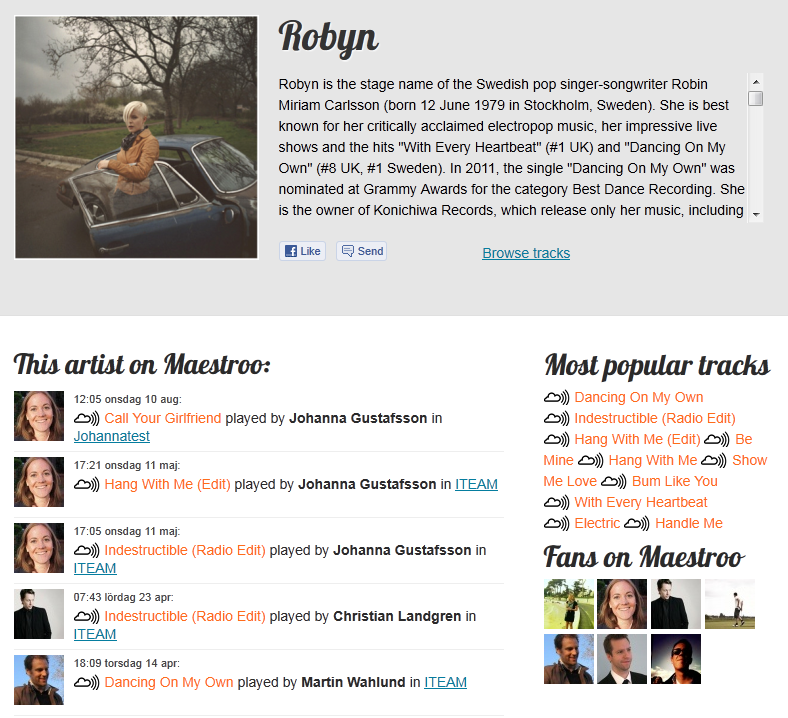
I detta exempel kommer jag att visa hur man sparar och hämtar upp information om när en låt spelats i vår musikspelare Maestroo. Förutom att Maestroo behöver informationen för att veta vilka användare som gillar vilken musik och vilka låtar som spelats tillsammans etc, så vill vi ha en egen sida för varje artist där det visas information om artisten och lite olika topplistor som senast spelade låtar och fans på Maestroo. Såhär:
Strukturen
För att uppnå detta sparar vi till RavenDB varje gång en låt spelas. Objektet TrackPlay håller reda på tid som låten spelades, användarnamn på den som spelade låten, rum som låten spelades i, själva låten som också är en egen entitet och i sin tur har ett namn, id, album och information om en artist osv.
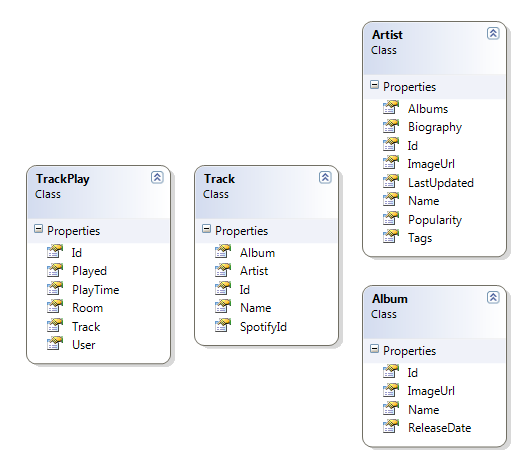
I en relationsdatabas skulle denna modell ha lagrats över flera huvudtabeller med nycklar och kopplingstabeller emellan för att knyta ihop informationen. I RavenDB ska vi istället spara modellen i ett dokument så att det blir lättare att plocka fram statistik i efterhand. T ex så här kan en TrackPlay med låt och allt se ut i Raven Studio (ni känner igen JSON-strukturen, eller hur?):
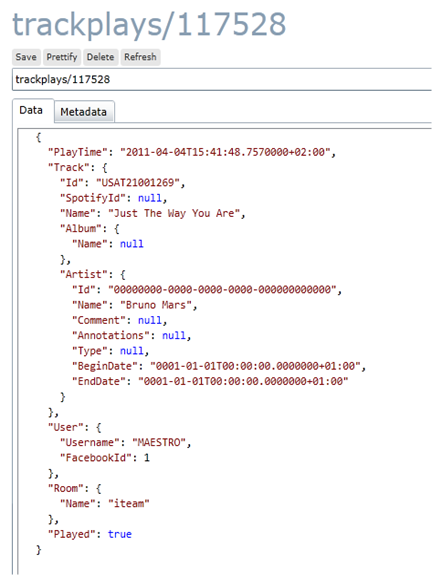
Som ni ser i bilden ovan så finns alla objektens egenskaper representerade men jag har bara fyllt på objekten med den data som jag anser vara relevant att spara i detta läge (det ska alltså vara den information jag kommer att behöva när jag senare ritar upp topplistorna).
Det enkla indexet
Det allra enklaste indexet är då det som används för att visa upp en lista på populäraste låtar för den här artisten. Det jag behöver i mitt index är tid som låten spelades (för att kunna sortera på senaste spelning) och artistnamn (för att kunna fråga efter en specifik artist).
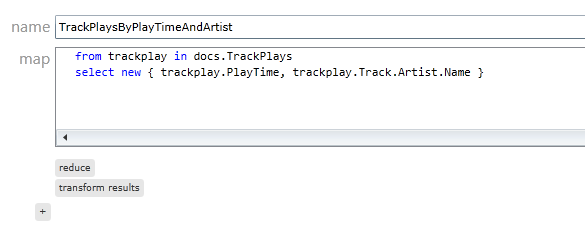
För att hämta en lista över senast spelade Robynlåtar kan jag nu ställa följade fråga mot indexet TrackPlaysByPlayTimeAndArtist:
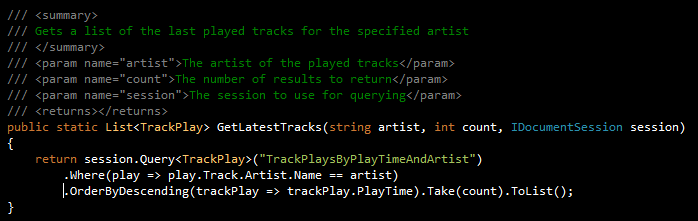
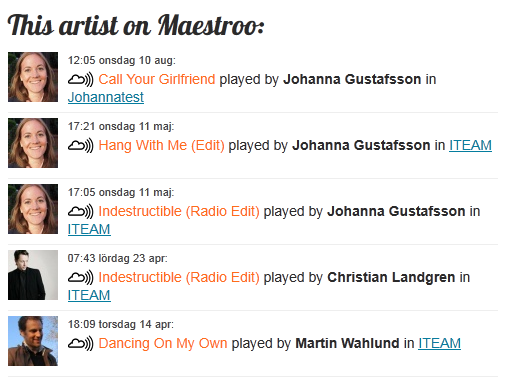
Och ut kommer information för att visa denna lista:
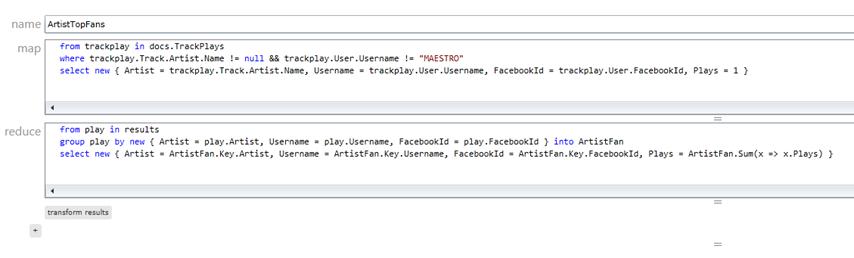
Index enligt map/reduce-mönstret
För att hämta ut en lista på en artists största fans, alltså vilka som har spelat låtar av en viss artist flest gånger, så använder jag ett map/reduce-index. Tanken här är att indexet byggs upp i två steg. I första steget gör jag precis som i indexet ovan, alltså väljer ut vilken information som behövs för att begränsa urvalet senare. För det är egentligen det vi vill; begränsa urvalet i indexet så att det blir så litet som möjligt. I nästa steg så grupperas urvalet om och reduceras ytterligare.
Indexet kan nu t ex användas på detta vis:
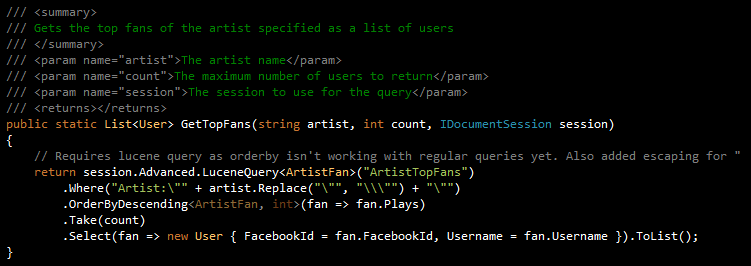
I queryn returneras ett fan av en artist:
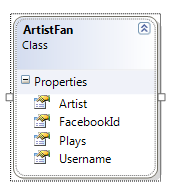
Och resultatet används för att visa användare som gillar artisten i fråga:

Fler bloggar om RavenDB kommer sannolikt att dyka upp i framtiden. Under tiden, ta en titt på våra tidigare tips:
http://tekniken.nu//Utvecklingstips/vad-ar-mapreduce-och-hur-anvander-man-det-i-nosql
http://tekniken.nu//Utvecklingstips/ravendb-music-store
Johanna Gustafsson
2011-09-02