

Vad är Map/Reduce och hur använder man det i NoSQL?
Först och främst, vad är NoSQL?
Innan vi börjar prata om Map/Reduce behöver vi nämna några ord om NoSQL. Vi kommer återkomma till denna teknik i ett antal bloggar och beröra olika delar av denna nya spännande teknik. NoSQL är egentligen samlingsnamnet på en ny typ av databasmotor som förenklas till att bara handla om en nyckel och en datamängd. Den stora paradigmskillnaden är att NoSQL databaser har en dynamisk struktur som går att utöka till skillnad från SQL databaser som kräver en strukturell förändring för att kunna ta emot ny typ av data. De allra flesta NoSQL-databaser bygger på en enkel nyckel som identifierar det data som ska lagras, i övrigt skiljer sig NoSQL-databaser mycket åt.
Den stora fördelen med traditionella SQL databaser är att de fungerar väldigt bra till de allra flesta typer av applikationer, men bara upp till en viss gräns då dess två största nackdelar tar vid – skalbarhet och prestanda.
Den stora fördelen med NoSQL databaser är att de är snabba, klarar av väldigt stora datamängder och antal poster. De har en dynamisk struktur och kan därför utökas i takt med att det data som sparas förändras. Den stora nackdelen är att de inte hanterar relationer och kan därför inte hjälpa till med att verifiera att all data är konsistent, dvs det finns alltså inga kontroller på att data inte lagras dubbelt. För att underlätta i bearbetningen av data i NoSQL finns en effektiv teknik från Google som hjälper till: Map/Reduce.
Map/Reduce - en teknik från Google
2004 lämnade Google in sin patentansökan för tekniken Map/Reduce som är en teknisk för att dela upp och distribuera arbetet med att bearbeta gigantiska mängder data. Map/Reduce används för att dela upp problem till mindre delar och sedan bearbeta och samla in svaren. Map/Reduce finns som ramverk till de flesta programspråk och används för att bryta ner allt ifrån matematiska beräkningar, bearbeta och förädla data, 3D renderingar och söka och sortera texter etc.
Tekniken är uppdelad i två steg
1- Map = Definiera en fast mängd data samt dela upp dessa i delsteg och distribuera
2- Reduce = Bearbeta delmängd och returnera ett bearbetat svar
Den stora vinsten med att dela upp sitt problem på detta sätt är att det blir lätt att distribuera beräkningsuppgiften, först på flera processorkärnor på servern och därefter på flera datorer. Amazon hyr till exempel ut datorkraft med hjälp av denna teknik som de kallar Elastic MapReduce så att företag kan köpa datorkraft på detta vis.
Användning av Map/Reduce inom NoSQL
Inom NoSQL används Map/Reduce flitigt för att skapa delmängder av en datamängd till ett beräknat format. Om man jämför med en traditionell SQL databas kan man lättast jämföra det med en indexed view. Dvs, en vy som är sammanplockad av flera underliggande datakällor men där man lagt ett index som håller indexet uppdaterat vid förändringar.
Ett problem inom NoSQL är att det inte finns relationer vilket gör det väldigt tidsödande att leta upp och sammanställa material som finns underliggande i sin datamängd.
Här följer ett par kodexempl som är förenklade men bygger på MongoDB syntax
Säg att man har en lista av låtar med kopplingar till artister och album. Inom SQL skulle detta sluta med tre tabeller med relationer till varandra. För att hämta en lista på alla artister i denna struktur ställs en enkel SQL-fråga:
SELECT * FROM artists
eller:
SELECT artistName FROM tracks GROUP BY artistName
Men inom NoSQL är svaret inte alltid lika enkelt. Eftersom strukturen är dynamisk kan det bli så att man inte har en lista av artister utan behöver gå igenom varje låt för att hämta artisterna:
var tracks = db.Tracks.find();
foreach (var track in tracks)
track.Album.Artist
Det behövs inte mer än några tusen rader i låtlistan innan detta blir långsamt. För att göra det snabbare så sätter vi upp ett index med Map/Reduce som genomför beräkningen i bakgrunden och förbereder en virtuell lista av artister som man sedan kan anropa direkt:
var artists = db.Artists.find();
Hos RavenDB som är en .NET baserad NoSQL-databas finns det stöd för Map/Reduce med LINQ vilket är väldigt smidigt för oss C# utvecklare. Uppdelningen är väldigt tydlig:
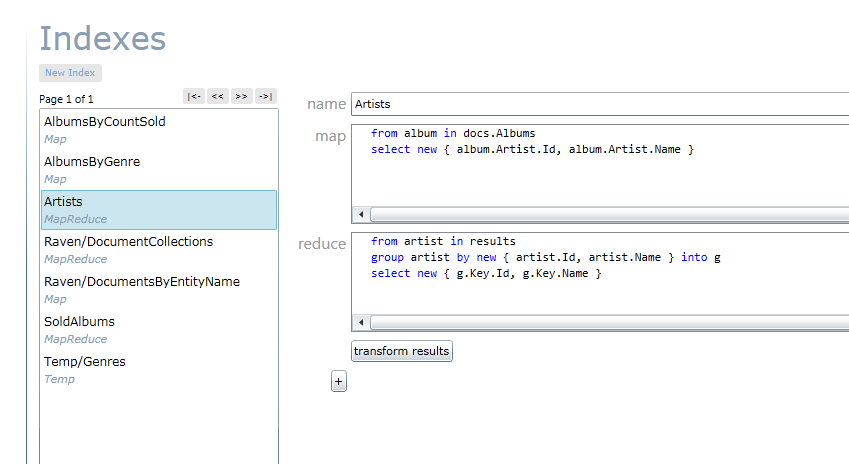
Man kan använda Map/Reduce på många sätt, antingen genom att skapa ny virtuell data, t ex som ovan sammanställa data från underliggande strukturer, föreslå vänner baserat på antalet gemensamma taggar, skapa topplistor baserat på försäljning etc, men också för att göra beräkningar (försäljningssiffror, statistik, sökningar osv).
Eftersom bara hälften av Map/Reduce indexet behöver köras för att avgöra om datan är invalid (Map) och eftersom endast den data som är förändrad behöver uppdateras (Reduce) sparas väldigt mycket resurser på detta sätt. Det är den stora vinsten med tekniken.
Läs mer om Map/Reduce och RavenDB här:
http://stackoverflow.com/questions/4253334/ravendb-map-reduce-example-using-net-client
och lite mer avancerat exempel:
http://ayende.com/Blog/archive/2010/03/14/map-reduce-ndash-a-visual-explanation.aspx
Mer läsning om NoSQL
Glöm inte heller att testa MongoDB konsol, klicka på ”Try it out” och skriv ”help” för lite tips:
http://www.mongodb.org/#shell
Om du gillar C# och LINQ ska du definitivt ladda ner RavenDB:
http://ravendb.net/download (tips: installera som service genom att köra raven.server.exe /install), administrera servern med ett fint Silverlight administrationsgränssnitt som kallas Raven Studio:http://localhost:8080 och titta på den ganska långa men informativa intervjun med Ayende Rahien:
(spola till slutet för att se lite bra kodexempel).
Christian Landgren
2011-04-18